如何理解大数据框架中的分区概念(如何理解大数据框架中的分区概念的含义)
导语:如何理解大数据框架中的分区概念
一、分布式问题背景
随着科技进步互联网的发展,各行各业产生的数据越来越多,由此催生了大量的数据处理需求。
任何事物的发展都不是一蹴而就的,一家公司成立之初10多人规模的时候,使用单台机器 shell 处理日志或者单个数据库就可以满足计算要求,并不需要分布式,并且效率很高
随着业务发展,需求的复杂度越来越高,单机处理的上限与性能日益凸显,为了突破瓶颈,就需要引入一些大数据的计算与存储框架,使用分布式计算和存储的方式,化整为零,分而治之。
二、分区在 Spark 中的实现1、一段 WordCount 程序Spark 中独创性的使用 RDD 来表示数据集,使用算子来表示任意的数据处理过程。
RDD 并不存储数据,RDD 只是表示对数据集的引用、计算方式、以及 RDD 之间的依赖关系。
下面贴出了一段程序,来计算经典的单词计数问题:
sc.textFile() .flatMap(_.split()) .map((_,1)) .reduceByKey(_+_) .foreach(println)大道至简,虽然这段程序并不复杂,但是当它跑在 Spark 集群上时,Spark 默默在背后做了以下的事情:
(1)生成两类任务,一类任务的逻辑是:从原始文件中领取一段属于自己的文件,计算单词数量;另一类任务的逻辑是:汇总前面任务的结果得到最终结果返回。
(2)调度器需要计算集群资源的使用情况,先把第一类任务按需发送到不同的服务器上执行;
(2)等到第一批任务全部执行完后,再提交第二批任务执行,它们会从第一批任务处读取它们的计算结果,做最终处理。
2、深入 textfile 的细节下面深入到一些细节中,首先需要介绍一下背景:
笔者本地部署了一个单机版的 hadoop 程序,并且设置了 blockSize 为 10m。
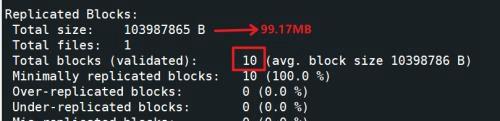
然后上传了一个 99M 的文件(就是代码中的文件)到 hdfs 上,此时文件 block 数量如下所示:
文件总大小为 99MB,在 hdfs 上一共有 10 个 block。
最终提交执行时,Spark 一共会产生 10 个 Task,每个 Task 读取一个 block 块文件
这个结论是如何得出来的?
此时需要引入一个概念:RDD 的分区。
在源码中,分区是 RDD 的一个非常重要的属性
可以想象,既然是分布式计算,那么每个 Task 肯定只需要计算自己的这一份数据。
而 Task 的数量是和分区数量一致的,每个分区对应一个 Task。
而 RDD 的分区数量是如何计算得到的?
答案是:每个 RDD 中都有一个 getPartitions 方法来计算分区。
让我们回到代码中。
sc.textFile 这一行代码,它返回的是一个 HadoopRDD,这个类里面定义了 getPartitions 方法。
抽去不需要的代码,简化核心代码如下:
override def getPartitions: Array[Partition] = { val allInputSplits = getInputFormat(jobConf).getSplits(jobConf, minPartitions) val inputSplits = if (ignoreEmptySplits) { allInputSplits.filter(_.getLength > 0) } else { allInputSplits } val array = new Array[Partition](inputSplits.size) for (i <- 0 until inputSplits.size) { array(i) = new HadoopPartition(id, i, inputSplits(i)) } array}首先使用 Hadoop 提供的 FileInputFormat 方法,遍历所有文件,再对每个文件遍历它的每个 block 文件,每个 block 文件得到一个 InputSplit。
在我的环境中,inputSplits 就是10个元素:
最终封装成 HadoopPartition 返回。
在生成 Task 的环节,就是利用这些 Partition 来生成对应的 Task。
3、其他算子的分区定义窄依赖的算子的分区数,会传承了前面的 RDD。比如此案例中的 flatMap 和 Map ,分区数都是 10 个,每个分区上下游算子都是 1 对 1 关系。
宽依赖的算子,比如 reduceByKey、groupByKey、join 等,都是根据参数传入的分区数决定;
如果参数没传分区数,会有一个算法来计算默认分区数(并不是坊间传闻的由上游的最大分区数决定)。
三、分区在 Kafka 中的实现Kafka 是一个大数据的消息中间件。
严格意义上来说,它并不是一个消息队列,因为它并不能做到全局的消息有序,所以这里称之为消息中间件。
Kafka 的作用使用四个字总结就是削峰填谷。
展开来说,Kafka 是在数据源头与数据计算之间,充当了消息缓冲的作用。
因为计算资源受限于机器的数量和每台机器的计算能力,而数据发送端(比如日志生成)则没有此限制。
一旦数据发送端生成数据超出了数据计算端的计算能力,系统就会发生不可预期的问题。
如果中间加入了 Kafka 这层缓冲,即使有海量数据过来,顶多是计算端来不及消费,数据有所积压,不会影响到整个系统的稳定。
为了充当好这个角色,对 Kafka 至少提出了以下的要求:
(1)必须是高性能的:每秒的吞吐量要跟上;
(2)必须是可扩展的:可扩展才能进一步提升吞吐;
(3)必须是高可靠的:增加数据的容错。
为此,Kafka 也设计了分区的概念,只有对数据分区了,才能把数据存储在不同的服务器上。
Kafka 的 Topic 可以在创建的时候,指定多个分区。每个分区可以指定多个副本。多个副本之间保持同步。
如下命令可以创建出包含 3 个分区,每个分区 3 备份的 topic
bin/kafka-topics.sh --zookeeper hadoop102:2181/kafka --create --replication-factor 3 --partitions 3 --topic topic_log在存储引擎中,分区一般和复制结合使用,使的每个分区的副本存储在多个节点上,提升数据的容错性。
四、分区带来的问题物极必反,天之道,损有余而补不足,分区在大数据领域可以带来化整为零、分而治之的正向效果,却也可能带来严重的问题。
总所周知,在做 Join 操作或 ReduceByKey 的操作时,上游任务需要把自己的数据,按照下游的分区数,分别发送给所有下游任务处理,相同的数据必须要发送给同一个任务处理,否则没法达到汇总的效果。
画个简单的示意图
如果此时,发送到下游某个 Task 的数据非常多,这将导致严重的性能问题:某个下游 Task 处理了 海量数据,其他 Task 却只有零星的数据需要处理。
这个问题也被称之为:数据倾斜。
关于数据倾斜的解决,最终思路都大同小异:使用一定的方法,避免热点数据进入同一个 Task 中。
它的解决方式,可以在 Hive框架、Spark框架相关的数据倾斜问题中找到,这里不详述。
本文内容由快快网络小莉创作整理编辑!