聚类集成的常见方法及思想(常见聚类算法及原理)
导语:集成聚类系列(一):基础聚类算法简介
聚类研究背景:
在机器学习中,一个重要的任务就是需要定量化描述数据中的集聚现象。聚类分析也是模式识别和数据挖掘领域一个极富有挑战性的研究方向。
聚类分析就是在无监督学习下数据对象的探索合适的簇的过程,在探索过程中,簇与簇之间的数据对象差异越来越明显,簇内的数据对象之间差异越来越小。
聚类分析是模式识别,机器学习领域中的一个重要的研究课题,而聚类作为数据分析的常用工具,其重要性也在很多领域得到广泛的认同。从聚类问题的提出到现在,已经有很多聚类方法:
基于划分的聚类方法,如K-means基于层次的聚类方法,如CURE基于网格的聚类方法,如STING基于密度的聚类方法,如DBSCAN基于神经网络的聚类方法,如SOM基于图的聚类方法,如Normalized cut上述的聚类方法各自有各自的优缺点,大家要意识到每个聚类方法都是都是基于不同理论背景并使用不同的学科方法来进行聚类分析的,但面对错综复杂的实际问题,并没有哪一种具体的聚类方法可以完美胜任所有数据的聚类分析的,具体问题需要具体分析。聚类算法的相似度量
聚类的最终目标就是在已知无标签的数据集上找到合适的簇,将这些无标签的数据合理的划分到合适的簇中。其中簇内的样本的相似度很高,不同簇的样本间相似度很低。所以聚类过程是需要计算数据间的相似性的。这里就需要有一个计算数据间相似性的标准。
一般地,每个数据点都可以用一个向量表示,因此可以使用距离d或者相似性s来衡量两个用向量表示的数据间的相似程度。由于表示数据点的向量元素具有不同的类型,可能是连续的,也可能是离散的,也可能有二者皆有的形式。因此距离函数d和相似系数s的定义也相应存在不同的形式。
假设有n个点的数据集合{x1,x2, x3,…xn},d_ij表示数据点x_i,x_j之间的距离,可以将n个数据点x_i,x_j间的距离写成矩阵形式。
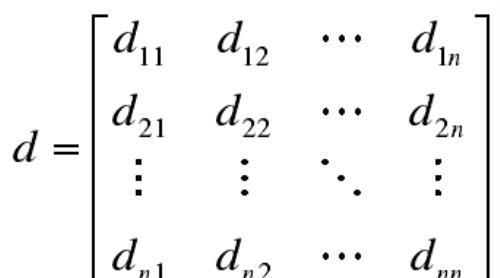
对于上述的数据集,s_ij表示数据点x_i与x_j间的相似度系数,也可以将n个数据对象的相似度系数写成矩阵形式。
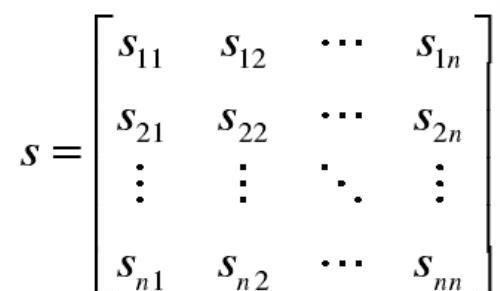
距离矩阵D的性质:在聚类分析中,距离矩阵一般满足自反性,对称性,非负性以及三角不等式等性质。
自反性,即: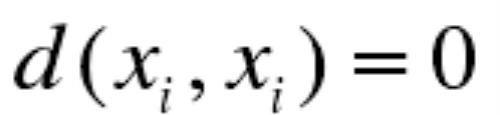
自反性
对称性,即: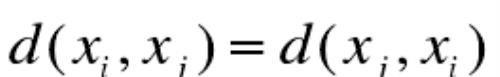
对称性
非负性,即: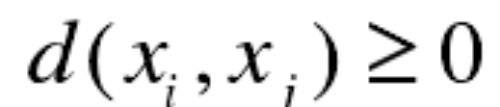
非负性
三角不等式,即: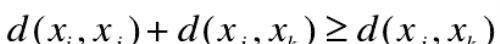
三角不等式
下表涵盖了不同的计算数据点xi=(x_i1,x_i2,…,x_in)与数据点xj=(x_j1,x_j2,…,x_jn)之间的距离或相似度的方式。
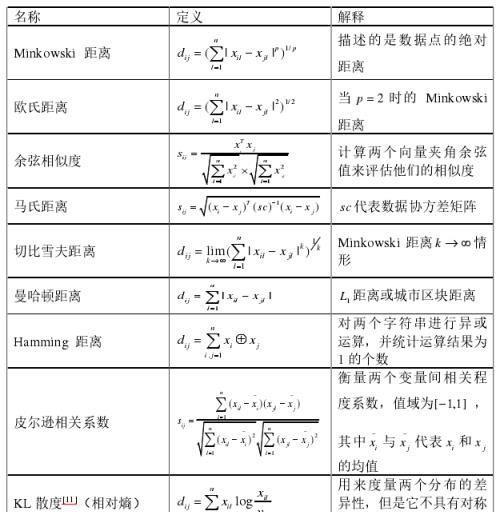
表1
典型的聚类分析算法
基于划分的方法
假定一个具有n个点的数据的集合,我们需要把数据集划分位k个子集,每个子集代表一个类别。常见的代表算法有kmeans,k-modes。K-means的具体思想:给定聚类个数k并随机选定k个聚类中心c_k,计算所有数据点与k个聚类中心的欧式距离,再对k个距离值进行排序,找到每个数据点最近的聚类中心。遍历完所有的数据点后,将每个聚类中心里的所有数据求平均值,将其更新为新的聚类中心。再重新遍历所有的数据点,再依次计算每个数据点与k个聚类中心的距离,找到它们与之对应的最近的聚类中心。遍历完后更新聚类中心,以此类推,直至误差值也就是每个簇内部数据点与中心的距离之和小于一个给定值并且聚类中心无变化时,就得到了最终的聚类结果。
基于划分的方法其实本质是对聚类中心逐步进行优化,不断将各个聚类中心进行重新分配,直到聚类中心位置不变,即获得最优解。
算法的优点:
当类与类容易分开时,k-means算法的效果相对较好;假设所有数据对象的数目,k为聚类个数,t为算法迭代的次数,则k-means时间复杂度为o(nKt),故算法可以处理样本量较大的数据。算法的缺点:
初始聚类中心选择的优劣,对聚类结果有很大的影响;只适用于凸状数据;需要人为设置聚类数目K,这对于调优超参数K带来一定的困扰。基于层次的方法
基于层次的聚类方法是指对给定数据对象集合做类似于层次状的分解,代表算法有CRUE,CHAMELEON,ROCK等。基于层次的聚类算法通常可以分为2种,自底而上的合并聚类和自顶向下的分裂聚类。
合并聚类开始会将每个数据对象看作一个子集,也就是有n个子集,然后对这些子集逐层依次进行聚类,直到满足无法合并的条件。分裂聚类是在一开始将所有的数据对象看成是一个集合,然后将其不断分解成子集直至满足不能再分解的条件为止。
基于层次的聚类算法通常会用平均距离,最大距离,最小距离作为衡量距离的方法,算法如果使用最大距离来度量类与类的距离时,称为最远邻聚类算法;当使用最小距离作为衡量类与类之间的距离时,称为邻聚类算法。
算法的优点:
不需要预先设定聚类个数;可以发现类的层次关系算法的缺点:
计算时间复杂度高;算法有可能导致聚类成链状,而无法形成层次结构。基于网络的方法
基于网格的聚类算法的目标是将数据按照维数划分为多层类似网格的结构,常见的基于网格聚类的算法如:STING,WAVECLUSTER等。STING聚类算法按照维数将数据空间划分为多个单元,子单元与原始数据的父单元构成一个层次结构。每个子单元存储子单元的相关信息(均值,极值等)。基于网格方法的时间复杂度为o(K)。其中K为最底层网格单元的数量。
算法的优点:
基于网格计算是相互独立的且互不干扰;时间复杂度低算法的缺点:
聚类的效果依赖于矩阵单元格划分的大小,单元格划分的细,聚类效果好,时间复杂度高;单元格划分的粗,聚类效果差。时间复杂度小。基于密度的方法:
基于密度的聚类方法是将数据密度较大的区域连接,主要对有空间性的数据进行聚类。该聚类方法将簇看作数据点密度相对较高的数据对象集。该方法具有较大的灵活性,能有效克服孤立点的干扰。常见的基于密度的聚类算法有:DBSCAN,DENCLUE,OPTICS等。
DBSCAN是基于密度的聚类方法。DBSCAN通过计算每个数据点的邻域来探寻密度可达对象集。如果一个点p的邻域内所包含密度可达对象点数目大于指定个数,则需要创建一个以点p为核心的新类。在此之后,DBSCAN算法反复从p的邻域中找寻密度可达对象集中元素,继续查找子集的密度可达对象集,当没有新的点构成聚类中心点时,聚类过程结束。
算法的优点:
应用比较广泛,收敛速度快算法的缺点:
不适合高维数据神经网络的方法
自组织映射(SOM)神经网络,实质上是一种浅层神经网络,只有输入层和隐藏层两层结构,隐藏层中的节点代表其需要聚集的类。每个输入的样本在隐藏层中找到一个和它匹配度最高的节点,称之为激活节点。SOM算法的具体思路是:首先初始化一些很小的随机数b并赋值给所有的映射节点,然后计算输入向量与输出映射节点的欧式距离值,排序后找出的值最小映射节点称为获胜节点,重新把输入向量映射到获胜节点,调节该获胜节点向量的权重值,同时按比例调节获胜节点邻域内的节点权重值,把所有的输入向量计算若干次,不断的参数优化后,相类似的输入向量被映射到输出层中临近的区域,达到算法终止条件,得到最终的输入向量的聚类。
算法的优点:
不需要定义聚类个数,SOM有很好的拓扑结构,可视性较好算法的缺点:
需要选择参数很多,调参数需要经验基于图的方法:
基于图的聚类方法根据给定的数据集,计算样本间的相似度矩阵,度矩阵以及拉普拉斯矩阵,并计算拉普拉斯的特征值和特征向量。然后选择合适数目的特征向量b并使用传统kmeans聚类,图聚类可以在非凸样本空间中聚类。
算法的优点:
比传统的kmeans聚类算法普适性更强,不仅可以用于凸数据,对于任意形状的数据空间也能得到很好的聚类。算法的缺点:
在进行聚类之前需要设置具体应用的尺度参数,通常需要一些经验。选择初始地聚类中心对整个聚类纯度影响很大。很难找到图划分的优化解,聚类个数选择对于整个聚类的结果有很大影响。免责声明:本站部份内容由优秀作者和原创用户编辑投稿,本站仅提供存储服务,不拥有所有权,不承担法律责任。若涉嫌侵权/违法的,请反馈,一经查实立刻删除内容。本文内容由快快网络小林创作整理编辑!