spss对应分析图(SPSS对应分析方法)
导语:SPSS对应分析
序曲
白田马上闻莺
李白(唐)
黄鹂啄紫椹,五月鸣桑枝。
我行不记日,误作阳春时。
蚕老客未归,白田已缫丝。
驱马又前去,扪心空自悲。
【译文】
黄鸥鸟啄食着柴色的桑椹,五月里鸣叫在桑树枝。
走啊走,我已不记得是什么时日,误以为现在还是阳春。
桑蚕已老,游子尚未还归,白田这地方已开始缫丝。
趋马继续前行,抚胸长叹空自悲叹。
【赏析】
这首诗写的是初夏风景,文字通俗易懂,而构思上却独具匠心。
诗人选取了黄莺、桑树、蚕三个日常生活中常见的意象,又把三者巧妙串连在一起,上承下启,前呼后应,构成一个严谨有序的艺术整体。就在这幅通俗、浅显的乡土风情画中,诗人寄托了他浪迹江湖、一事无成的悲哀。所谓“我行不记日,误作阳春时”、“蚕老客未归”,言下之意是阳春已过,初夏来临,而自己大业未就,虚掷光阴,空度岁月。
正是桑间黄莺的啼鸣惊醒了诗人,时临收获的季节,应当珍惜年华,不能再作无目的漫游了。但是,驱马向前,扪心自问,前途是如此渺茫,令诗人倍感悲凉,尾联收笔联系深层的现实,而表达的情感正是一种怀才不遇、报国无门的思想情绪,其中也含有羁旅的愁苦以及对家乡的思念之情
注:来源于 古诗文网
对应分析简介
什么是对应分析?
对应分析(Correspondence analysis)也可称为关联分析、R-Q型因子分析,可看做是分析交叉表的一种方法,可以将交叉表中所包含的信息在低维的空间中进行降维投射,然后选取信息在其中最重要的两条轴上的投射点,用图形进行表示;能够将几组看不出任何联系的数据,通过视觉上可以接受的定位图展现出来。
对应分析法可以揭示同一变量的各个类别之间的差异,以及不同变量各个类别之间的对应关系。主要应用在市场细分、产品定位、地质研究以及计算机工程等领域中。
对应分析法整个处理过程由两部分组成:表格和关联图。对应分析法中的表格是一个二维的表格,由行和列组成。每一行代表事物的一个属性,依次排开。列则代表不同的事物本身,它由样本集合构成,排列顺序并没有特别的要求。在关联图上,各个样本都浓缩为一个点集合,而样本的属性变量在图上同样也是以点集合的形式显示出来。
对应分析为我们可以提供三个方面的信息
变量之间的信息样本之间的信息变量与样本之间的信息上述三方面信息都可以通过二维图呈现出来
当对两个分类变量进行的对应分析称为简单对应分析;对两个以上的分类变量进行的对应分析称为多重对应分析。(2)基本思想
对应分析的基本思想就是将一个列联表的行和列中各元素的比例结构以点的形式在较低维的空间中表示出来。(列联表的每一行及每一列均以二维图上的一个点来表示,以直观、简洁的形式描述属性变量各种状态之间的相互关系及不同属性变量之间的相互关系。)
对应分析将变量及变量之间的联系同时反映在一张二维或三维的散点图上,并使联系密切的类别点较集中,联系疏远的类别点较分散;通过观察对应分布图就能直观地把握变量类别之间的联系。
(3)分析步骤
对应分析法整个处理过程由两部分组成:列联表和关联图(行列变量分类的对应分布图)。因此,对应分析大致有四大步骤,分别为:
编制交叉列联表根据原始矩阵进行对应变换行变量和列变量的分类降维处理绘制行列变量分类的对应分布图SPSS实现对应分析
示例1:研究者收集了苏格兰北部5387名小学生眼睛与头发颜色的数据,其中眼睛有深、棕、蓝、浅4种颜色,头发有金、红、棕、黑、深5种颜色。研究者希望知道头发和眼睛颜色间存在何种关联,即某种头发颜色的人其眼睛更倾向于何种颜色?

1. 参数说明
打开 分析—降维—对应分析
(1)主页面:定义行列变量及取值范围
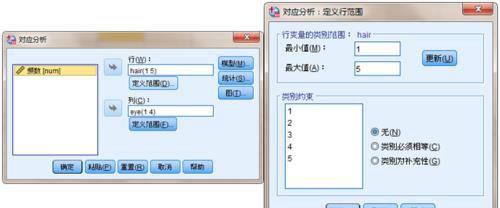 行/列:选择行/列变量,并确定取值范围。最小值/最大值:输入行/列变量的最小值与最大值,并点击更新即可。类别的度—无:表示不再对分类值重新分组类别的度—类别必须相等:表示指定哪些分类值合并为一类类别的度—类别为补充值:表示指定某些分类不参与分析
行/列:选择行/列变量,并确定取值范围。最小值/最大值:输入行/列变量的最小值与最大值,并点击更新即可。类别的度—无:表示不再对分类值重新分组类别的度—类别必须相等:表示指定哪些分类值合并为一类类别的度—类别为补充值:表示指定某些分类不参与分析(2)模型 选项框:
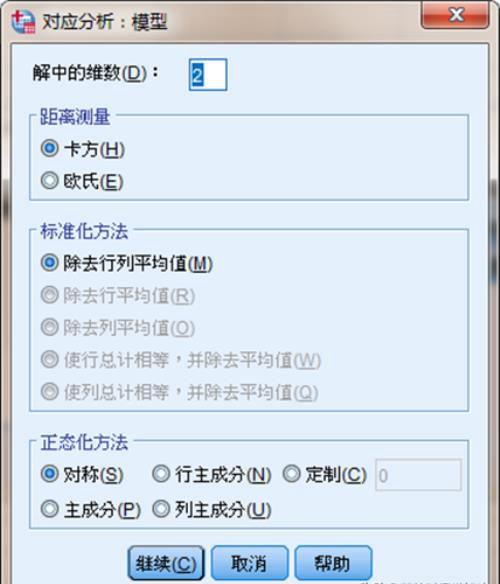 解中的维数:输入行列变量分类最终提取的因子个数,默认为2,表示各分类点显示在二维平面上。距离测量:指定对应表的行和列之间距离的测量,对分类变量通常使用卡方,其他定距变量使用欧氏距离。标准化方法:指定数据的标准化处理方式。
解中的维数:输入行列变量分类最终提取的因子个数,默认为2,表示各分类点显示在二维平面上。距离测量:指定对应表的行和列之间距离的测量,对分类变量通常使用卡方,其他定距变量使用欧氏距离。标准化方法:指定数据的标准化处理方式。除去行列平均值 :为默认值,在标准化时将行合计均数和列合计均数的影响均都移去,即行、列类别间均数的差异不再对结果产生影响。如:不同地区所有产品平均销售额的不同不再纳入分析,不同产品所有地区平均销售额差异也不再纳入分析,在结果中呈现的是行、列变量类别间的交互作用,诸如A产品销量在各地都高于其他产品,或者上海地区的各种产品销售额都高于其他地区这类信息均不进入分析。
删除行均值或删除列均值:在标准化时只移除行或列变量合计均数差异的影响。以行变量为例,如果某一类别的均数与另一类别均数差始终为一常数,如A产品在各地的效率大约都比D产品高2万,则该方法会将这种差异的影响消除。
使行总和相等删除均值或使列总和相等删除均值:在标准化时首先将原始数据除以行或列合计,然后再移除行或列均数差异影响。
正态化方法:指定数据的正态化方式对称:重点分析行列变量各类别之间的联系,而非每个变量各类别之间的差异
主要行:重点分析行变量各类别之间的差异
主要列:重点分析列变量各类别之间的差异
主要:希望同时分析行列变量各类别之间的差异
(3)统计 选项框:指定生成的数值输出
对应表:带有行和列边际总计的输入变量的交叉表格。行点概览:对于每个行类别,有得分、质量、惯量、对维惯量的贡献,以及维对点惯量的贡献。列点概览: 对于每个列类别,有得分、质量、惯量、对维惯量的贡献,以及维对点惯量的贡献。行概要文件:对于每个行类别,为跨列变量类别的分布。列概要文件:对于每个列类别,为跨行变量类别的分布。对应表的排列:对应表重新组织为:行和列根据第一维上的得分按递增顺序排列。或者,可指定将为其生成置换表的最大维数。将为从 1 到指定数字的每一维分别生成一个置换表。行点的置信统计:包括所有非补充行点的标准差和相关性。列点的置信统计:包括所有非补充列点的标准差和相关性。
(4)图 选项框:指定生成哪些图
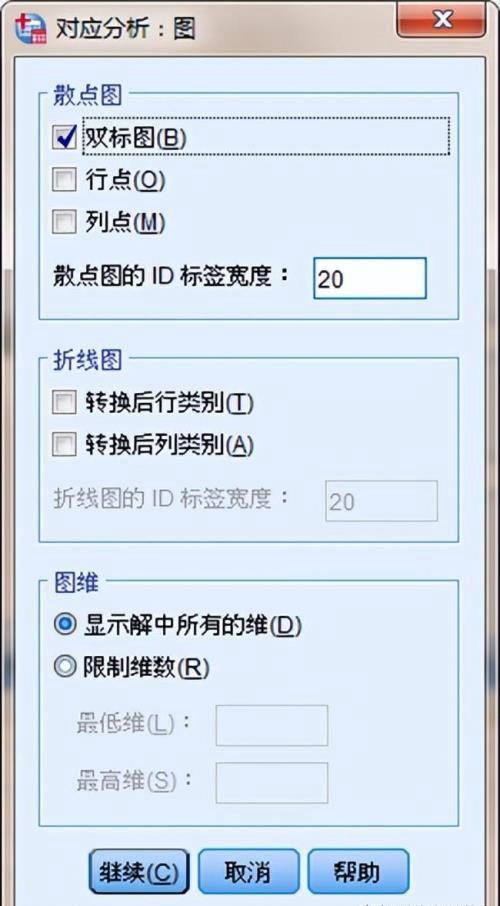 散点图:生成维的所有成对图矩阵
散点图:生成维的所有成对图矩阵双标图:生成行点和列点的联合图矩阵。如果选择了主标准化,则双标图不可用。
行点:生成行点图的矩阵。
列点:生成列点图的矩阵。
图:为所选变量的每一维生成一个图。可用的线图包括:已转换的行类别:根据初始行类别值的对应行得分生成这些值的图。
已转换的列类别:根据初始列类别值的对应列得分生成这些值的图。
图:可用以控制在输出中显示的维数。显示解中的所有维数:解中的所有维数都显示在散点图矩阵中。
限制维数:显示的维数限制为绘制的对。如果限制维数,则必须选择要绘制的最低和最高维数。最低维数的范围可从 1 到解中的维数减 1,并且针对较高维数绘制。最高维数值的范围可从 2 到解中的维数,表示要在绘制维对时使用的最高维数。此指定项适用于所有请求的多维图。
2. 参数选择
数据加权:将num 进行加权将 hair 选入 行 列表框,单击定义范围,将数值范围定义为1-5将 eye 选入 行 列表框,单击定义范围,将数值范围定义为1-43. 结果分析
版权信息:对应分析模块是荷兰Leiden大学DTTS课题组的研究成果。 交叉列联表:列联表中的活动边际为频数合计
交叉列联表:列联表中的活动边际为频数合计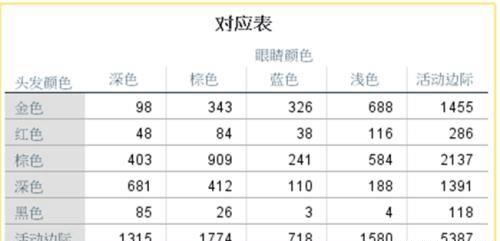 摘要:在对应分析中,最多可提取的维度数等于两变量的最小类别数-1,但往往前2-3个维度就携带了绝大多数信息,摘要表可给出所提取的每个维度(因子)所携带的信息量,从而帮助确定需要使用多少维度对结果进行解释。
摘要:在对应分析中,最多可提取的维度数等于两变量的最小类别数-1,但往往前2-3个维度就携带了绝大多数信息,摘要表可给出所提取的每个维度(因子)所携带的信息量,从而帮助确定需要使用多少维度对结果进行解释。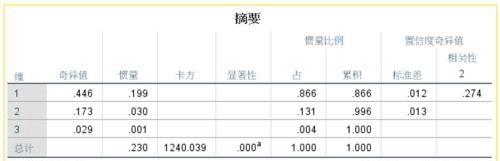
奇异值与惯量:奇异值的平方就是惯量,相当于因子分析汇总的特征根,用于说明对应分析各个维度结果能够解释列表中两变量联系的程度;所有维度惯量的综合则仍然可以用来表示总信息量的大小。
卡方检验与p值:检验行变量与列变量间是否存在关联,可以看作是对应分析适用条件的检验,只有当行变量和列变量有关联时,才需要使用对应分析对这种联系加以分析。本例中卡方检验值为1240.039,p<0.05,所以拒绝零假设,认为行变量与列变量有显著的相关关系。
方差解释比例:表明每个维度所携带的信息量,实际上就是按照每个维度的惯量占总惯量的综合比例计算而来。由表可知,第一维占总信息量的 0.199/0.23=86.6%,第二维占总信息量的13.1%,第三维占总信息量的0.4%。显然,前两个维度携带了绝大部分信息。
行点总览:行变量(头发颜色)各类别的分析结果概况。给出各类别在各维度上的评分,以及相应的信息贡献量两大类信息。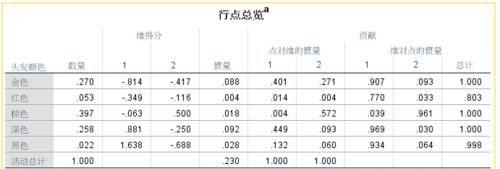
数量Mass:实际上就是各类别的构成比,如发色为金色的共1455人,占总数比例为27%;比例的大小可近似地反映相应的指标是否稳定,因为比例越高,说明频数越多,相应的分析结果就越不易受个别极端样本的影响。
维得分:给出各类别在相关维度上的评分,首先给出的是在默认提出的两个维度上各类别的因子负荷值(空间坐标值),随后的惯量列则给出了惯量在行变量中的分解情况,反映了总惯量(0.23)中分布由各行变量类别所提供的部分,数值越大,说明该类别对惯量的贡献越大。
贡献:首先给出在各维度上信息量在各类别间的分解情况。在本例中,第一维度的信息主要被金色、深色和黑色3个类别所携带,在第一维度区别较好;随后给出各类别的信息在各维度上的分布比例,如金色的总信息量中有90.7%分布在第一维度,只有9.3%在第二维度。综合观察,除棕色外,绝大多数信息的都分布在第一维。最右侧给出了各维度信息比例之和,可见红色这一类别信息只提取了80.3%的信息。
列点总览:列变量(眼睛颜色)各类别的分析结果概况。给出各类别在各维度上的评分,以及相应的信息贡献量两大类信息。与行点总览分析相同 对应分析图
对应分析图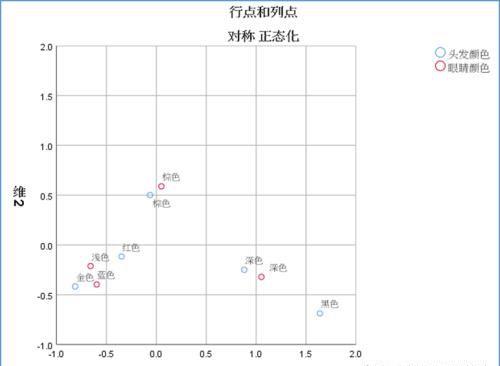
考察同一变量的区分度:首先分别考察行变量、列变量各类别间是否被清晰地分开了,可以分别检查在各个维度上的区分情况,如果同一变量不同类别在某个方向哈桑靠的较近,则说明这些类别在该维度上区别不大。在本例中,可以看到无论是头发颜色还是眼睛颜色在空间位置上分的比较开。
考察不同变量的类别联系:这是对应分析的核心问题,一般而言,落在从图形原点处出发相同方位上大致相同区域内的不同变量的分类点彼此有联系,散点间距离越近,说明关联倾向约明显;散点离原点越远,也说明关联倾向越明显。
从上图可看出,研究棕色与头发棕色靠的比较近,显然两种特征之间存在关联;眼睛深色和头发黑色存在关联;头发金色和眼睛蓝色、浅色存在联系。
4. 语法
WEIGHT BY num.CORRESPONDENCE TABLE=hair(1 5) BY eye(1 4)/DIMENSIONS=2/MEASURE=CHISQ/STANDARDIZE=RCMEAN/NORMALIZATION=SYMMETRICAL/PRINT=TABLE RPOINTS CPOINTS/PLOT=NDIM(1,MAX) BIPLOT(20).免责声明:本站部份内容由优秀作者和原创用户编辑投稿,本站仅提供存储服务,不拥有所有权,不承担法律责任。若涉嫌侵权/违法的,请反馈,一经查实立刻删除内容。本文内容由快快网络小萱创作整理编辑!