kmeas聚类分析(kmeas聚类算法简介)
导语:聚类分析之——Kmeans算法(一)
聚类分析是一种静态数据分析方法,常被用于数据挖掘、机器学习、模式识别等领域,聚类是一种无监督式的学习方法。它是在未知样本类别的情况下,通过计算样本彼此间的距离(欧式距离,马式距离,汉明距离,余弦距离等)来估计样本所属类别。从结构性来划分,聚类方法分为自上而下和自下而上两种方法。聚类的算法有很多种,大约几十种,K-means算法是十大经典数据挖掘算法之一。
K-means算法是最为经典的基于划分的聚类方法,是十大经典数据挖掘算法之一。它是一种自下而上的聚类方法。K-means算法最大的优点是好理解、简单、运行速度快,但只能应用于连续性的数据;缺点是聚类的结果与我们初始设置的中心点的选择有直接关系,并且需要我们自己提供聚类的数目,但是可以通过多次聚类取最佳的结果来设定初始的聚类数目,如果当我们不知道样本集将要聚成多少个类别的时候,那么这时候不适合用kmeans算法,推荐使用其他方法来聚类,如(hierarchical 或meanshift)。
K-means算法的基本思想是:以空间中k个点为中心进行聚类,对最靠近他们的对象归类。通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果,大概就是这个意思,“物以类聚、人以群分”。具体流程如下:
数据分析交流:283296032
首先输入一个k的值,此值是我们自己设定的,k表示将数据集经过聚类得到的分组个数。
从数据集中随机选择k个数据点作为初始中心点。
对集合中每一个数据点,分别计算与每一个初始中心点的距离,数据点离哪一个中心的越近,就归类此类。
通过均值等方法对聚成的类再进行新的中心点确定。
若新的中心点与原来的中心点之间的距离小于一个阈值(设置好的一个阈值),说明比较稳定,那么此聚类达到了我们的期望,算法结束。
如果新的中心点与原来的中心点之间的距离很大,那么需要迭代以上的3-5步骤。
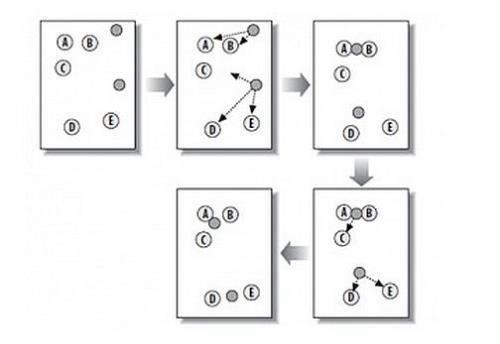
聚类基本流程图
K-means算法的关键点在于初始中心的选择和距离公式。
KMeans的应用场景非常多,除了一般的聚类场景(例如对用户进行分群组等)外,我们还可以用KMeans实现单变量的离散化,因为一般的等频和等距的离散化方法往往会忽略变量中潜在的分布特征,而基于聚类的离散化可以一定程度地保留变量的分布特征。
免责声明:本站部份内容由优秀作者和原创用户编辑投稿,本站仅提供存储服务,不拥有所有权,不承担法律责任。若涉嫌侵权/违法的,请反馈,一经查实立刻删除内容。本文内容由快快网络小彤创作整理编辑!